This series bridges the gap between theoretical math and hands-on machine learning. Each article combines intuitive explanations, real-world analogies, and executable Python code to show how mathematical concepts directly enable ML algorithms. Whether you’re preparing for interviews, building a portfolio, or deepening your understanding, these articles serve as both a study guide and a practical reference.
Complete
Mathematics for ML
This series bridges the gap between theoretical math and hands-on machine learning. From Linear Algebra to Information Theory.
Curriculum Overview: 7 Chapters Found
Chapters
Sequential Learning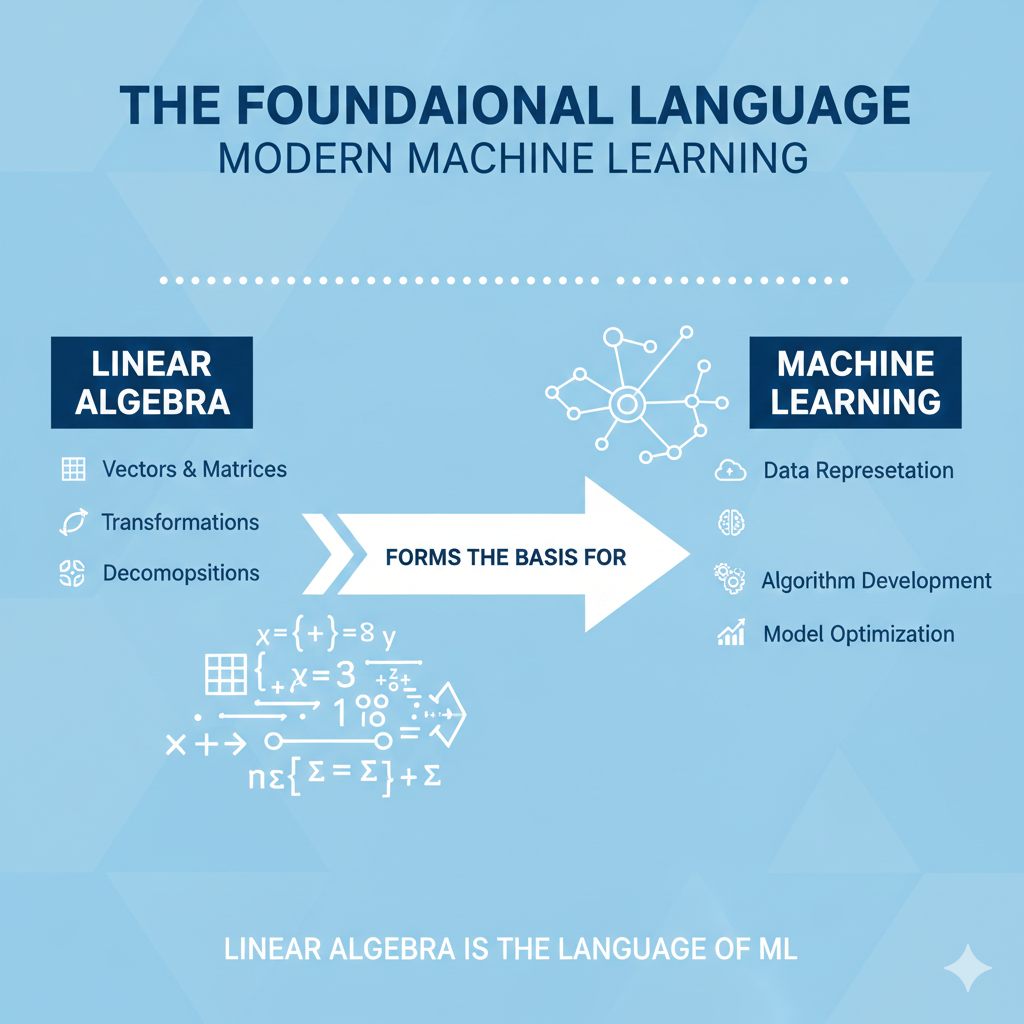
Article
7 min read
Linear Algebra in ML From Matrices to Embeddings
Linear algebra forms the fundamental language of modern machine learning. This article explores how seemingly abstract concepts—vectors, matrices, decompositions—materialize into practical applications ranging from dimensionality reduction to semantic representation learning.
Article
9 min read
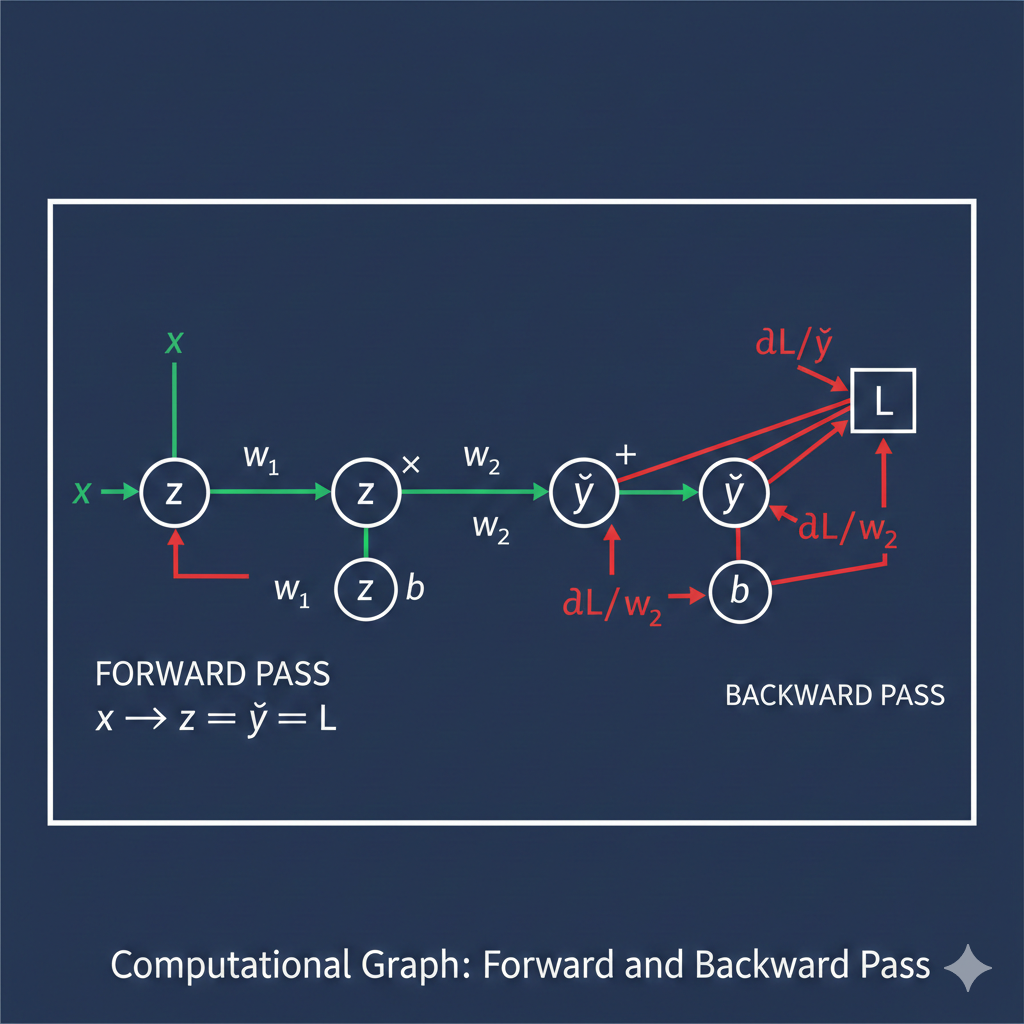
Calculus for ML: Gradients, Optimization and the Chain rule
If linear algebra provides the vocabulary of machine learning, calculus provides the grammar—it tells us how things change. This article demystifies the calculus concepts that power modern ML
Article
8 min read
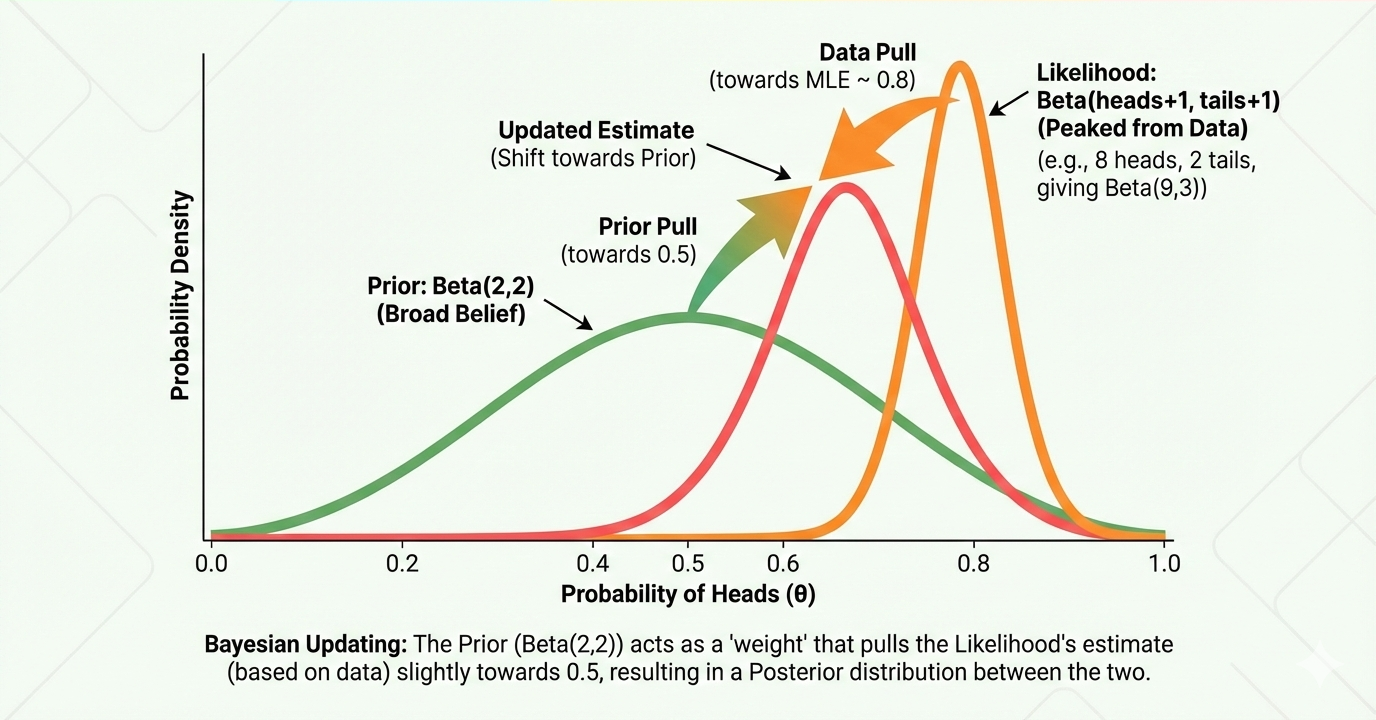
Probability for ML From Bayes' Theorem to Generative Models
Probability theory is the mathematics of uncertainty—and machine learning is all about making decisions under uncertainty. This article demystifies the probabilistic foundations that underpin everything from spam filters to large language models.

Article
9 min read
Optimization for ML: Beyond Gradient Descent
This article explores the optimization landscape: from convex to non‑convex problems, from first‑order to second‑order methods, and from simple SGD to adaptive algorithms like Adam and RMSprop.
Article
5 min read
Statistics for ML: Evaluation and Inference
Move beyond simple accuracy. Explore the statistical foundations of model evaluation: from hypothesis testing and confidence intervals to the fundamental bias‑variance tradeoff.

Article
4 min read
Advanced Multivariable Calculus: The Geometry of Deep Learning
Master the advanced geometry of loss landscapes. Explore the Jacobian and Hessian matrices, Taylor expansions, and the complex calculus that powers backpropagation in modern deep learning.

Article
4 min read
Information Theory: The Convergence of Machine Intelligence
The grand finale. Discover how Entropy, KL Divergence, and the Principle of Maximum Entropy unify all mathematical pillars into a single framework for measuring and mastering information.